
Im direkten Vergleich mit dem G92, dem bis dato neusten Chip aus dem Hause Nvidia, hat man ein wahres Monster geschaffen! Mit etwa 1,4 Milliarden Transistoren wurde die Anzahl nahezu verdoppelt (754 Mio. bei G92)! Festgehalten hat man am bewährten 65 nm Fertigungsprozess (TSMC), der gemeinsam mit umfangreichen Stromsparfunktionen die maximale Leistungsaufnahme entsprechender Grafikkarten drosseln soll. Dennoch bewegt man sich mit 236 Watt für das Spitzenmodell der neuen GeForce-Serie auf sehr hohem Niveau, was eine gute Kühlung aller Komponenten notwendig macht.
Durch neuartige Mechanismen hat man allerdings Wege gefunden die Leistungsaufnahme in verschiedenen Betriebsmodi weiter zu senken und beispielsweise eine GeForce 9800 GTX zu unterbieten. Nach Angaben Nvidias benötigen GeForce GTX 200 Grafikkarten im Idle lediglich 25 Watt (9800 GTX: 45 Watt) und begnügen sich bei der Wiedergabe von Blu-ray-Material mit moderaten 35 Watt (9800 GTX: 50 Watt). Dank HybridPower lässt sich bei bestimmten Systemkonfigurationen (integrierte Grafik) die Grafikkarten komplett abschalten: Bei weniger grafikintensiven Anwendungen, beispielsweise bei E-Mail und Internet-Surfen, wird mit HybridPower die mGPU genutzt und die externe Grafik über den SMBUS abgeschaltet (angeblich 0 Watt Leistungsaufnahme bei Off-Modus). Das senkt die Hitzeentwicklung im Gehäuse, den Geräuschpegel und den gesamten Stromverbrauch.
;)
;)
Im folgenden Bild ist die Architektur des GT200 übersichtlich dargestellt und lässt sich in drei wesentliche Teile splitten: Scheduler für anfallende Operationen (violett), Recheneinheiten für Abarbeitung (schwarz), Speicher-Interfaces und ROPs (blau). Wie in den vorherigen Unified-Shader-Architekturen hat man auch bei der jüngsten Auflage die Rechenpower in Clustern zusammengefasst und erreicht dadurch ein hohes Maß an Flexibilität bei der Konfiguration und eine maximale Chipausbeute pro Wafer. Ein solcher Cluster (10 Stück im Falle des unteren Bildes), namentlich bei Nvidia kurz als TPC (Thread Processing Cluster) verankert, fasst verschiedene Komponenten zu einem Bündel zusammen. Dazu gehören jeweils drei so genannter Streaming Multiprocessors (SMs), die wiederum aus acht einzelnen Shader Processors (SPs) bestehen. Neu ist hier beispielsweise ein lokaler Speicher innerhalb eines SM, der die direkte und schnellstmögliche Kommunkation zwischen SPs möglich macht. Dadurch will man weitere Latenzen in der Praxis einsparen, da nicht mehr der umständliche Weg über höher liegende Speicherebenen (Frame Buffer) gegangen werden muss. Komplettiert wird ein TPC durch entsprechende Filtereinheiten (jeweils 8 TUs) und einen großen L1-Cache-Speicher.
Zu den weiteren Architektur-Verbesserungen gehören neue Scheduler, die im Bereich des Texturing bis zu 20 Prozent effektiver arbeiten sollen, eine verdoppelte Anzahl an Registersätzen für komplexere Shader-Operationen, Double-Precision (64 Bit) Gleitkomma-Berechnungen nach IEEE 754R, optimierte Geometrie-Shader und vieles mehr. Nicht zu vergessen ist die vollständige Unterstützung der PhysX-Engine. Nach wie vor verzichtet man allerdings auf eine Implementierung von Microsofts DirectX 10.1 und setzt auch bei der GTX-Serie weiterhin auf DX10. Nach Angaben der Ingenieure wurde während der Entwicklung des GT200 der Support von DX10.1 evaluiert, allerdings für nicht wichtig eingestuft. Stattdessen hat man sich auf eine verbesserte Performance in DX10 konzentriert.
Im unteren Teil der Architektur-Übersicht befinden sich die ROPs (Raster Operation Processors) und die jeweils 64 Bit breiten Interfaces zum externen GDDR3-Speicher. Anhand der Skizze lassen sich auch leicht die Hardware-Skalierung bzw. die technischen Daten auf der folgenden Seite nachvollziehen.
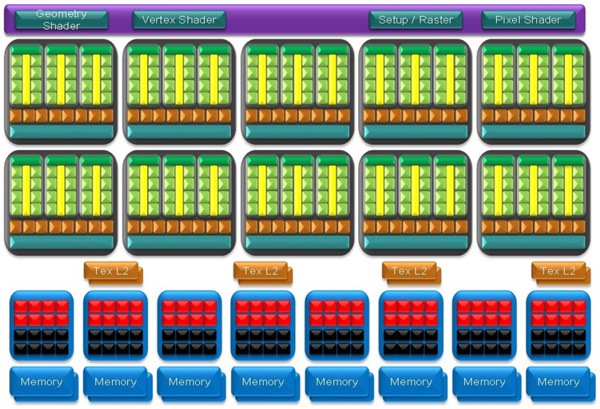
Nvidias GT200-Chip (hier: GTX 280) setzt auf geballte Rechenpower
und kommt mit mehr Shader-Cores als jede Unified-Generation zuvor.
Eine stabile und schnelle Internetverbindung gehört heute zur Grundausstattung vieler Haushalte. Streaming, Cloud-Dienste und Online-Gaming stellen hohe Anforderungen an die...
Eine solide Server-Infrastruktur bildet das Fundament jedes erfolgreichen Tech-Projekts. Ob Webanwendung, API-Backend oder datenintensiver Dienst – wer die Server-Infrastruktur-Performance von...
Intel hat neue Desktop-Prozessoren der Serie Intel Core Ultra 200S Plus vorgestellt. Zu den ersten Modellen gehören der Intel Core...
Die Sharkoon OfficePal KB70W soll laut Hersteller ein besonders komfortables und leises Tippgefühl für den Büroalltag bieten. Dafür setzt die...
Der Arbeitsspeicher ist ein zentraler Bestandteil jedes Computers und hat einen entscheidenden Einfluss auf die Leistungsfähigkeit des Systems. Je nach...

Mit der iCHILL Frostbite bietet INNO3D eine GeForce RTX 5090 Grafikkarte mit Wasserkühlblock von Alphacool an. Wir hatten die Gelegenheit diesen extravaganten Boliden im Testlab auf Herz und Nieren zu prüfen.

Mit der GeForce RTX 5070 Ti HOF Gaming bietet Grafikkarten-Spezialist KFA2 einen besonders extravaganten Boliden mit großem OC-Potenzial an. Wir durften im Praxistest einen Blick auf die Black Edition der Karte werfen.

Im günstigeren Preissegment hat Nvidia die GeForce RTX 5070 installiert, die auf der abgespeckten Blackwell-Variante GB205 basiert. Wir haben uns ein Custom-Design von Hersteller KFA2 im Test genauer angesehen.